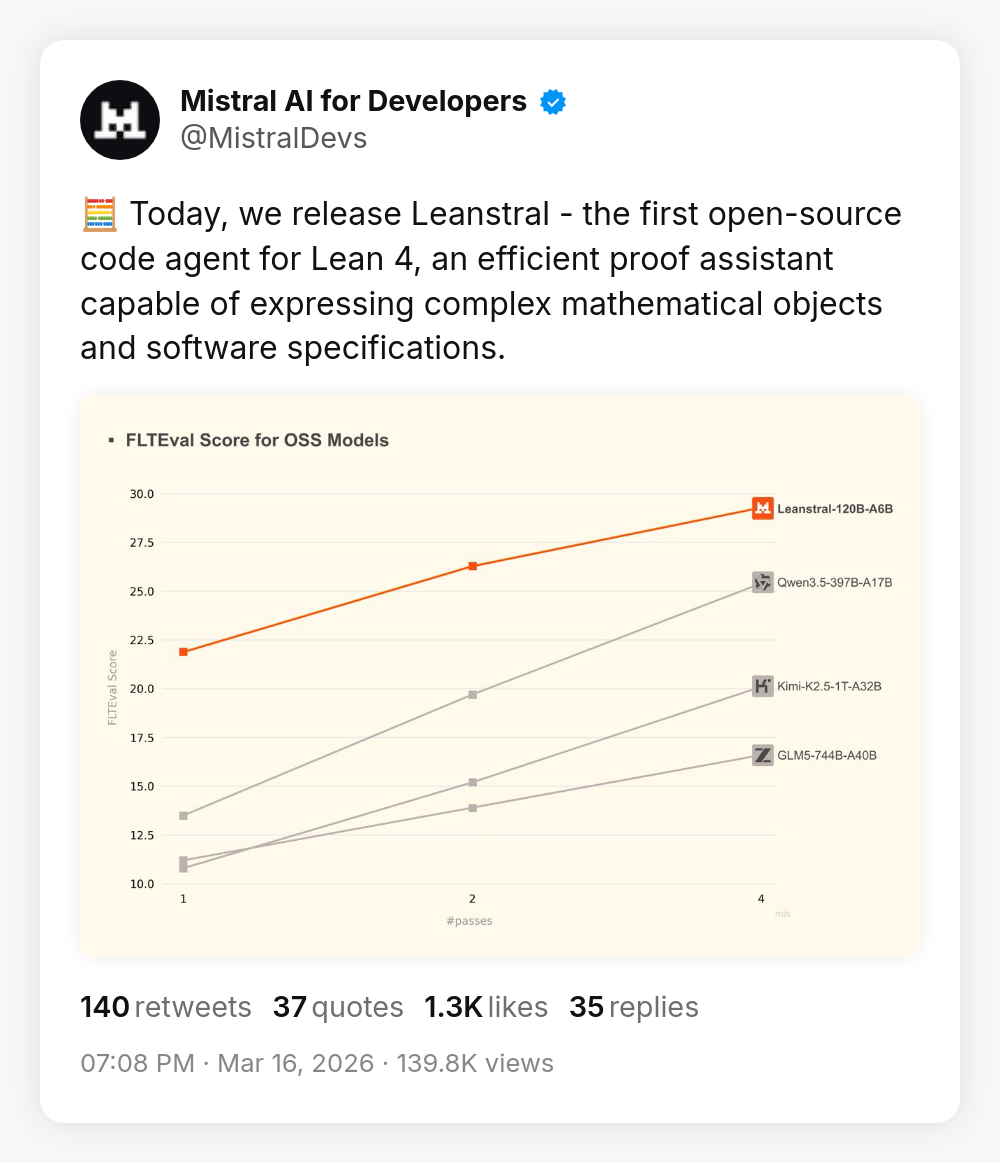
|
The Brief
NVIDIA Is Selling You an Operating System
By Adam Placker · 2 min read · OPINION
Jensen Huang unveiled seven chips at GTC this week. The most important one is the chip NVIDIA didn't design. Three months after closing the $20B Groq acqui-hire, Groq's SRAM-based LPU is already integrated into Vera Rubin, claiming 35x better tokens-per-watt. That integration speed tells you everything about what NVIDIA is actually building.
The keynote pitch was inference efficiency - Vera Rubin delivering 10x throughput per watt at one-tenth the cost per token versus Blackwell. Great numbers. But the real product isn't a chip. It's a stack. Custom silicon (Groq LPUs), inference orchestration (Dynamo), an agent runtime (NemoClaw) - all designed to work together and optimized to work best with each other. NVIDIA isn't selling GPUs anymore. It's selling an operating system for inference.
This is the Mellanox playbook running a second time. Find the layer where the next bottleneck lives, buy it, integrate it, make the full stack the product. And the timing tracks. Inference now accounts for 85% of enterprise AI budgets, driven by agentic loops, RAG pipelines, and always-on deployments. It went from a line item to the line item, and NVIDIA is planting itself at the center of where the money actually gets spent.
| |
The question for CTOs isn't whether Vera Rubin is impressive. It's whether you're buying infrastructure or subscribing to someone else's roadmap.
|
|
But here's what the keynote glossed over. Custom ASIC shipments from cloud providers are projected to grow 44.6% in 2026 - nearly triple the growth rate of GPUs. Google, Meta, Amazon, and Anthropic are all building inference-specific silicon. Midjourney moved from H100s to TPU v6e and cut monthly inference spend by 67%. Suddenly the Groq deal looks less like offense and more like defense - absorbing the best inference-specific hardware before it became someone else's moat.
The open-source framing of Dynamo is the clever bit. It gives NVIDIA plausible "we're not locking you in" cover, but the hardware optimization runs so deep that open-source-on-NVIDIA-hardware is still NVIDIA-dependent. Cursor, Perplexity, PayPal, and Pinterest are already running production workloads on it. That's real switching costs accumulating in real time.
If you're evaluating inference this quarter, NVIDIA's integrated stack will almost certainly benchmark best. Just know what you're signing up for. Every layer you adopt makes the exit harder - and that's not a bug in their strategy, it's the entire point.
|